
jpeg压缩算法(四):编码
前言
JPEG压缩的最后一步是对数据进行哈弗曼编码(Huffman coding),哈弗曼几乎是所有压缩算法的基础,它的基本原理是根据数据中元素的使用频率,调整元素的编码长度,以得到更高的压缩比。
举个例子,比如下面这段数据
AABCBABBCDBBDDBAABDBBDABBBBDDEDBD |
这段数据里面包含了33个字符,每种字符出现的次数统计如下
如果我们用我们常见的定长编码,每个字符都是3个bit。
那么这段文字共需要333 = 99个bit来保存,但如果我们根据字符出现的概率,使用如下的编码
那么这段文字共需要$36 + 115 + 42 + 29 + 41 = 63$个bit来保存,压缩比为63%,哈弗曼编码一般都是使用二叉树来生成的,这样得到的编码符合前缀规则,也就是较短的编码不能够是较长编码的前缀,比如上面这个编码,就是由下面的这颗二叉树生成的。
首先,学习JPEG编码步骤我们需要先了解一下霍夫曼编码(Huffman coding)和行程编码(RLE)
霍夫曼编码原理
TODO…
行程编码原理(RLE)
TODO…
JPEG中的编码
我们回到JPEG压缩上,回顾上一节的内容,经过数据量化,我们现在要处理的数据是一串一维数组,举例如下: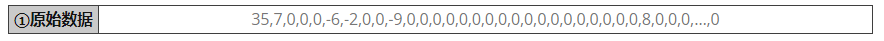
在实际的压缩过程中,数据中的0出现的概率非常高,所以首先要做的事情,是对其中的0进行处理,把数据中的非零的数据,以及数据前面0的个数作为一个处理单元。
如果其中某个单元的0的个数超过16,则需要分成每16个一组,如果最后一个单元全都是0,则使用特殊字符“EOB”表示,EOB意思就是“后面的数据全都是0”,
其中(15,0)表示16个0,接下来我们要处理的是括号里右面的数字,这个数字的取值范围在-20472047之间,JPEG提供了一张标准的码表用于对这些数字编码:15之间,所以这两个数可以合并成一个byte,高四位是前面0的个数,后四位是后面数字的位数。
举例来说,第一个单元中的“35”这个数字,在表中的位置是长度为6的那组,所对应的bit码是“100011”,而“-6”的编码是”001″,由于这种编码附带长度信息,所以我们的数据变成了如下的格式。
括号中前两个数字分都在0
对于括号前面的数字的编码,就要使用到我们提到的哈弗曼编码了,比如下面这张表,就是一张针对数据中的第一个单元,也就是直流(DC)部分的哈弗曼表,由于直流部分没有前置的0,所以取值范围在015之间。255之间,所以对应的哈弗曼表会更大一些
举例来说,示例中的DC部分的数据是0x06,对应的二进制编码是“100”,而对于后面的交流部分,取值范围在0
这样经过哈弗曼编码,并且序列化后,最终数据成为如下形式
最终我们使用了10个字节的空间保存了原本长度为64的数组,至此JPEG的主要压缩算法结束,这些数据就是保存在jpg文件中的最终数据。
参考
https://thecodeway.com/blog/?p=522
相关链接
[1] http://www.impulseadventure.com/photo/jpeg-huffman-coding.html
[2] http://www.mysanco.cn/index.php?class=wenku&action=wenku_item&id=96
[3] http://www.codingnow.com/2000/download/jpeg.txt
[4] http://jingyan.baidu.com/article/cbf0e500f1ce562eaa2893f4.html
[5] http://www.codeproject.com/Articles/83225/A-Simple-JPEG-Encoder-in-C
 wechat
wechat alipay
alipay




